Printer Friendly
No Aggregates, what's a girl to do?
Those who read our PostGIS series may be wondering why the examples we chose were not the same as what we did for
PostGIS. Sadly SQL Server 2008 does not have any built-in spatial aggregates such as those you would find in PostGIS (e.g. ST_Union, ST_Collect, ST_Extent, ST_MakeLine etc.).
Not to fret because Isaac Kunen and his compadres have been filling in the gaps in SQL Server 2008 spatial support. These gaps are filled in
with a tool kit called SQL Server Spatial Tools and can be downloaded from Code Plex at
http://www.codeplex.com/sqlspatialtools, not to be confused with Morten's SQL Spatial Tools we covered in the first tutorial.
Keep in mind that SQL Server 2008 Spatial tools is a moving target with new functionality constantly added. As of this writing it has the following
packaged goodies list in our order of importance:
- GeographyUnionAggregate - similar to ST_Union aggregate in PostGIS and other spatial databases. This is only for Geography types.
- GeographyCollectionAggregate - similiar to ST_Collect aggregate in PostGIS.
- GeometryEnvelopeAggregate - this is similar to what PostGIS people call the ST_Extent aggregate.
- Affine Transform - these are functions that make things such as Translate, Rotate, Scale possible and PostGIS folks will recognize this as the Affine family of functions (ST_Affine, ST_Translate, ST_Rotate, ST_TransScale). No its not Projection support. This
is generally useful for doing motion pictures or maintaining spatial relationships between related objects such as when you are developing your robot, Robie. It is a bit scary if Robie gets up and forgets the rest of his body behind. Those of us who suffer or have suffered from sleep paralysis know the feeling and it ain't pleasant.
Also useful
for tiling and map dicing.
- A couple of Linear Referencing functions for both Geometry and Geography - locate along, interpolateBetween useful for pinpointing determining street address or resolving a street address to a geometry/geography point. Again parallels exist in PostGIS and other spatial databases.
- DensifyGeography - I suspect this is a complement to SQL Server Geometry Reduce function (or in PostGIS lingo ST_Simplify, ST_SimplifyPreserveTopology).
In this exercise we shall demonstrate how to compile the latest build, install and brief examples of using. As of this writing, the latest version is
change Set 15818 released in September 12, 2008.
Compiling and Installing
Compiling
Note you can skip the compile step if you are satisfied with not having the latest and greatest and just download the original August compiled release. I would encourage you to be brave though since the newer version
contains a lot of improvements include the GeographyCollectionAggregate.
- Download the latest source version from http://www.codeplex.com/sqlspatialtools/SourceControl/ListDownloadableCommits.aspx. For those people
who are comfortable with using Subversion you can download directly from the codeplex SVN interface at
https://sqlspatialtools.svn.codeplex.com/svn (I recommend Tortoise SVN client http://tortoisesvn.net/downloads as a nice plugin to windows explorer for downloading and browsing SVN sources.
- If you don't have the full Visual Studio 2008 (e.g. Standard, Professional not that Business Studio thing SQL Server packages in to confuse you) or Visual Studio C# Express, you can download Visual Studio 2008 C# Express for free from http://www.microsoft.com/express/download/default.aspx and run the setup to get in business. Note older versions of Visual Studio will not work.
- Open the solution (.sln) by using the File->Open Project option file in Visual Studio 2008 / C# Express) and Right-Click on the Solution and click Build Solution.
Installing
Now after we have compiled, the assembly file will be located in the SpatialTools\bin\Release folder and be called
SQLSpatialTools.dll. Before we can start using, we'll need to load this assembly and the function stubs into our database.
- First if you have your SQL Server 2008 on a different box from where you compiled, copy over the SQLSpatialTools.dll to a folder on that server.
- Open up the Register.sql file in the bin\Release folder with your SQL Server 2008 Studio Manager
- Next as the Readme.txt in the bin\Release folder states, there are 2 things you need to change in the Register.sql file.
- Change
USE [] to --> USE testspatial
replacing testspatial with whatever you called your database.
- Change
create assembly SQLSpatialTools from '' to create assembly SQLSpatialTools from 'C:\SQLSpatialTools.dll' or whereever you copy the file. Note if you want you can delete the dll file later after you have registered it since
the registration process copies the dll into the Database anyway.
- The other SQL files have some simple use cases of the functions you can try out so give them a test drive to make sure you installed right.
- Not only should the test sql files work, but you should also be able to see a site like this from SQL Server 2008 Studio -
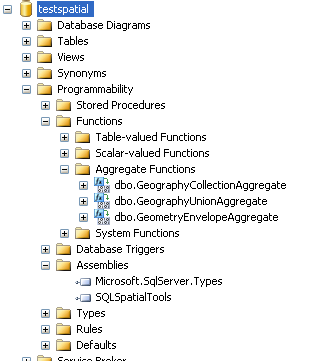
Now for the fun
Union the towns so we get one geometry per town and insert into a new table called towns_singular_geodetic
SELECT town, dbo.GeographyUnionAggregate(geom) As geom
INTO towns_singular_geodetic
FROM towns_geodetic
GROUP BY town;
--Creates 351 rows.
compare to
SELECT COUNT(*) from towns_geodetic;
Which gives us 1241 rows.
What towns are adjacent to Boston?
SELECT t.town
FROM (SELECT geom FROM towns_singular_geodetic WHERE town = 'BOSTON') as boston
INNER JOIN towns_singular_geodetic As t
ON boston.geom.STIntersects(t.geom) = 1
ORDER BY t.town
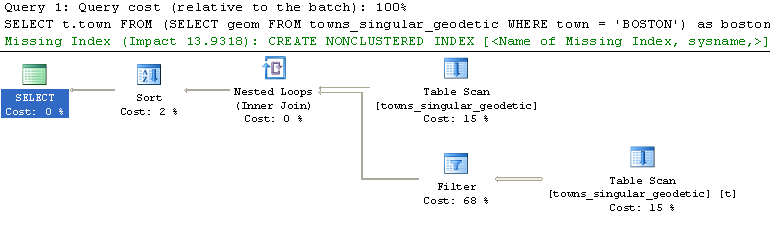
--This query took a whole 9 seconds and returned 13 towns. Hmm what could be wrong. Is this the best we can do?
If we run the Actual Execution Plan - we see that SQL Server tells us in very subtle terms that we are idiots.
 .
.
If only that message about the missing index were in Red instead of Green, I just might have thought there was a problem :).
The Power of Indexes
Well looking at our query we see a WHERE based on town and we are obviously doing spatial calculations that can benefit
from a spatial index. A spatial index in SQL Server 2008 always relies on a clustered index so lets make our town a clustered primary since we have one town per record now and a spatial index.
Gotchas
- Can't make a field a Primary Key if it allows nulls
- Need preferably a primary key that is clustered for spatial index
- For some reason when using the WYSIWIG it wants to drop the table first. So I'm relying on my memory
of ANSI DDL SQL which oddly works.
- Some apps don't like unicode nvarchar so I need to convert that nvarchar(255) to varchar(50)
Run the below in SQL Server 2008 Studio/Express.
ALTER TABLE dbo.towns_singular_geodetic ALTER COLUMN town varchar(50) NOT NULL
GO
ALTER TABLE [dbo].[towns_singular_geodetic] ADD PRIMARY KEY CLUSTERED
(
town ASC
)
GO
ALTER TABLE dbo.towns_singular_geodetic ALTER COLUMN geom geography NOT NULL
GO
CREATE SPATIAL INDEX [geom_sidx] ON [dbo].[towns_singular_geodetic]
(
[geom]
)USING GEOGRAPHY_GRID
WITH (
GRIDS =(LEVEL_1 = MEDIUM,LEVEL_2 = MEDIUM,LEVEL_3 = MEDIUM,LEVEL_4 = MEDIUM),
CELLS_PER_OBJECT = 16) ;
After all that work rerunning our query - we are using the clustered index now, but no spatial index and speed is not improved.
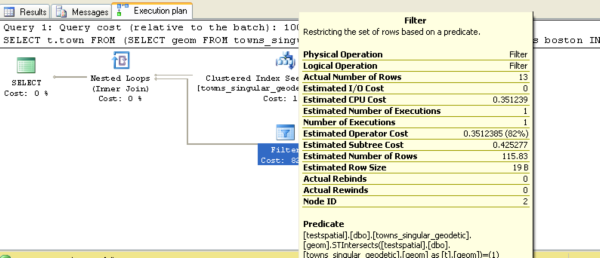
Sadly it seems to get better performance (in fact down to less than 1 sec), we have to put in a hint to tell it to use
the spatial index.
SELECT t.town
FROM (SELECT geom FROM towns_singular_geodetic WHERE town = 'BOSTON') as boston
INNER JOIN towns_singular_geodetic As t WITH(INDEX(geom_sidx))
ON boston.geom.STIntersects(t.geom) = 1
ORDER BY t.town
A snapshot of part of the show plan is here and we see that mystical warning flag telling us we have no stats for that spatial index:

So we have a workaround, but the workaround to me is very unappealing, perhaps because I come from the old school of thought
that databases should know more about the state of the data than I do and the ideal solution is not to give the database hints, but figure
out why the database doesn't think it needs to use the spatial index. I can go into a whole diatribe of why HINTS are bad, but
I'll try to refrain from doing so since I'll just bore people with my incessant whining and start some mini holy wars along the way.
As my big brother likes saying -- When a fine piece of American rocketry doesn't work right, you better hope you have
a Russian Cosmonaut hanging around and laughing hysterically. It took me a while to get the full thrust of that joke and appreciate my brother's twisted sense of humor.
Back to Basics
What does all the above nonsense mean. In a nutshell - sophisticated machinery is nice, but don't let the complexity of that
machinery shield you from the fundamentals. Admittedly its hard and I thank my lucky stars that I was brought up in a time before computers and programming got
too complicated for a little kid to tear apart and successfully put back together. There is nothing as exhilarating for a nerd kid as being able to tear apart his/her toys and realizing "Yes I have the power to fix this myself".
There are a couple of things that most relational databases share with each other regardless of how simple or
complex they are
- They are cost-based systems. You can imagine a little economist sitting in there being handed stats and saying
ah based on these summaries and my impressive knowledge of database economics, I think the best plan (course of action) to take is this.
- Statistics are usually represented as some sort of histogram thing defining some distribution of data in your indexes or selected fields. SQL Server usually when you create indexes on a field
it creates statistics objects that go with it so most users don't even know what this is. Reader Connor's stat man description for more gory details. Statistics are updated and created frequently and
if you follow good SQL Server best practices - you don't quite know why but you use the wizard to create a maintenance plan
that does all these wonderful things behind the scenes like reindexing and updating your statistics periodically for you. You use the tuning wizard, pass it a load of queries - saying This is my common workload and it in return says ah we need to start gathering these statistics and we need these indexes to improve the speed of your queries and it generates a script that adds these indexes and
creates these objects called statistics and you blindly run the script not looking at it because you are in very good hands. In wizard we trust. Life is great with the wizard.
- Heuristics - basically rules of thumb that if you have x pockets of data here and are asking for y then it makes sense to use this and that. To an economist
this boils down to statistics, normalizing them, and then throwing coefficients in front of them to create one big ass impressive looking equation.
- Good databases just like good economists, make bad decisions when given bad statistics or incomplete statistics
- Not just statistics makes them behave badly, but coming up with coefficients is inherently a black art and they sometimes
put a cost coefficient in front of a value that is too high or too low. It seems in SQL Server's case, there is no way
to fiddle with these coefficients.
With all these great gadgets and wizards, things work and the world is good except when things don't work and then you look up at that Russian Cosmonaut hanging above you in his modest machine with his pint of warm vodka in hand laughing hysterically.
Why is he laughing hysterically? Because ironically he has never seen anything quite like this gorgeous machine you have which looks especially magical in his drunken state, but even in his drunken stupor he
recognizes your problem, but you, fully sober, and having used this machine for so long are still scratching your head. His machine is not quite so complicated and he has seen the problem less disguised before.
He has fewer magical wizards to summon to help out so he relies more on his hard-earned cultivated understanding of fundamentals of how things are supposed to work to guide him. He is one with his machine and you are not because in wizard you trusted,
but the wizard seems to be doing very strange things lately.
So what's the problem here? Why must SQL Server be told to use the spatial index sometimes though not all the time? Well it is no surprise, spatial is a bit of a new animal to SQL Server and the planner is probably a bit puzzled by this new beast. I
thought perhaps its because
there are no statistics for the spatial index and in fact you can't create statistics for the spatial index. If you try to do this:
CREATE STATISTICS [geom_towns_singular_geodetic] ON [dbo].[towns_singular_geodetic]([geom])
GO
You get this - Msg 1978, Level 16, State 1, Line 1
Column 'geom' in table 'dbo.towns_singular_geodetic' is of a type that is invalid for use as a key column in an index or statistics.
Even after trying to force statistics with update towns_singular_geodetic statistics. Still no statistics
appeared for the spatial index. One day magically the statistics appeared for both towns_singular_geodetic and towns_geodetic (SQL Server is known to create statistics behind the scenes when the mood strikes it like all good wizards), but they were for some mystical tables called sys.extended..index... that contained cells, grids and stuff - I couldn't see these things,
I couldn't select from them, but I could create statistics on them too just like the wizard can.
I tried figuring out how this happened by dropping the index and readding and as expected the statistics went away and I'm sure they will come back.
Contrasting and comparing between PostgreSQL and SQL Server. PostgreSQL lets you fiddle with coefficients and for 8.3+ you can fiddle down to individual functions, but you can't HINT. No Hinting is allowed.
SQL Server allows you to hint all you want but no fiddling with its coefficients (that is the wizards realm). So what to do what to do. When you feel like HINTING go for SQL Server, but if you are in the mood
to write big ass equations go for PostgreSQL :). Well truth be known in most cases you neither have to HINT nor write big ass equations except when the planner seems to be fumbling.
Note: In the other scenario of Part 2, SQL Server gladly used the spatial index without any hints and even without stats, but this time it is not. Why not? Because
sometimes you don't need to look at statistics to know it is better to use something and your rule of thumb just drastically prefers one over the other. If you have millions of people in a crowd
and you are looking for a person with a blue-checkered shirt, you can guess without looking at the distribution of the index that if you have an index by shirt-color type, it would probably help to use that index. However if you have only
2 people in a crowd and you are looking for someone with a blue-checkered shirt, it is probably faster to just scan the crowd than pulling out your index and cross-referencing with the crowd.
This exercise was a bit of a round about. If I really wanted to know which towns are adjacent to Boston I really don't need to do a spatial union, I could do the below query and the below query
magically uses the spatial index without any hinting and returns the same 13 records in the same under 1 sec speed.
SELECT t.town
FROM (SELECT geom FROM towns_geodetic WHERE town = 'BOSTON') as boston
INNER JOIN towns_geodetic As t
ON boston.geom.STIntersects(t.geom) = 1
GROUP BY t.town
ORDER BY t.town
So what does this tell us. Possibly the large size of each spatial geometry in the unioned version and the relative small size of the table is
making SQL Server think bah -- scanning the table is cheaper. So the cost coefficients it is applying to the spatial index may be over-estimated. Perhaps this will be improved in Service Pack 1.
Spatial Helper Stored procedures
SQL Server 2008 comes with a couple of spatial helper stored procedures to help us diagnose problems. Below are some sample uses.
DECLARE @qg geography
SELECT @qg = geom FROM towns_singular_geodetic WHERE town = 'BOSTON'
EXEC sp_help_spatial_geography_index 'towns_singular_geodetic', 'geom_sidx', 1,@qg
Post Comments About Part 3: Getting Started With SQL Server 2008 Spatial: Spatial Aggregates and More


